


 购买普通授权版(
购买普通授权版( 导入插件并试用
导入插件并试用
 赞赏(0)
赞赏(0)
更新记录
1.0.6(2023-12-19)
修改价格
1.0.5(2023-12-18)
修改链接
1.0.4(2023-12-18)
说明文档添加链接
查看更多平台兼容性
云端兼容性
| 阿里云 | 腾讯云 | 支付宝云 |
|---|---|---|
| √ | √ | × |
云函数类插件通用教程
使用云函数类插件的前提是:使用HBuilderX 2.9+
能上线的AI
- uni-ai 是个好东西。
- 但只能基于AI已有知识进行回答,回答的内容很多不是我们想要的。
- 我们要的是针对自己的业务场景,基于AI的智能回答。
- 所以我们需要一个基于AI的智能问答平台。
- 所以我开发了这个插件。
原理
基于腾讯向量数据库,将文本转为向量,然后将向量存储到云数据库,然后通过向量相似度,从云数据库中查询相似度最高的向量,然后将向量转为文本,通过AI进行回答,返回给客户端。
必备条件
- ui-ai-chat
- 腾讯云账号
- 腾讯云向量数据库(TDS)目前免费 向量数据库申请地址
配置中心
位置:uniCloud/cloudfunctions/common/uni-config-center/ttai-data/config.json 注意要去掉注释
{
// 腾讯数据库配置 空为使用公共测试库
"tx_url": "", //外网连接地址
"account": "",// 默认是root
"api_key": "",
"database": "", //空为默认值:default_db
"collection":"", //空为使用当前APPID
"local_url": "" //不为空时,将使用本地化部署的数据库
}申请完成以后配置好相关的参数就可以使用了。 如果不申请也可以使用,但只能用于测试,数据库会不定期进行清理,所以不推荐使用。
本地部署需要修改database,collection,local_url
希望本地化部署数据库的或配置不明白的,加我微信:tbbanjia
开发计划
- [x] 对接腾讯向量数据库
- [ ] 上传文档,基于文档回答
- [ ] 本地化部署向量数据库
- [ ] 记录聊天历史
- [x] 压缩聊天历史 节省RMB,目前先使用uni-ai自带的功能
- [ ] 可配置化AI提示
- [ ] AI请求云对象/云函数/外部API
安装方式
- 下载uni-ai-chat
- 下载TTAI-DATA
- 点击右上角下载并导入插件
- 在聊天页chat.vue 引入云对象
// 在 export default上面添加 const ttai_data = uniCloud.importObject('tt_ai_data') - 找到发送信息的位置,在发送前调用云函数,找到 let task = uniCoTask,在上面添加
// 在发送之前,将最后一条messages.content修改成从数据库读取 if (messages.length > 0) { //合并用户的问题 messages.role == "user" let messages_user = messages.filter(item => item.role == "user").map(item => item.content).join(' ') //只取messages_user最后的400个字符 if (messages_user.length > 400) { messages_user = messages_user.substring(messages_user.length - 400) } //搜索向量数据库 let search_data = await ttai_data.searchDocument([messages_user]) if(search_data.length > 0){ //如果 score>0.8的话,说明有数据,这个值可以根据需要改动 不能大于1,值越大,匹配度越高 if(search_data[0].score >= 0.8) { // 更新最后一条消息 // 这里可以修改提示词 let prompt = `${search_data[0].text}\n\n使用上面的内容回答问题:${messages[messages.length - 1].content}` messages[messages.length - 1].content = prompt } } } - 打开 http://localhost:8080/#/uni_modules/ttai-data/pages/data/list 添加AI的学习内容
谋生
承接各种AI应用级的程序开发。有需要的可以加我微信:tbbanjia
云对象调用方法:
const ttai_data = uniCloud.importObject('tt_ai_data')
// 查询数据 async searchDocument(texts=["文本1", "文本2"], limit = 1, ids = [])
// texts: 文本数组 文本长度不超过400个字符 多了会被截断
// limit: 限制返回结果数量
// ids: 过滤条件,指定返回结果的id数组 ids=["id1", "id2"]
// 返回值:
// [{ "id": "5035a41ba51f640e4a448397341b91d5", "score": 0.861058, "text": "向量数据库部署架构:向量数据库采用分布式部署架构,每个节点相互通信和协调,实现数据存储与检索。客户端请求通过 Load balance 分发到各节点上" }]
const res = await ttai_data.searchDocument(texts, limit, ids)
// 添加修改 async upsertDocument(texts)
// 限制:每次最多添加1000条数据,每条数据长度不超过400个字符
// texts: 文本数组 texts=["文本1", "文本2"]
// 返回值:
// true
const res = await ttai_data.upsertDocument(texts)
// 数据列表 async queryDocument(limit = 10, offset = 0)
// limit: 限制返回结果数量
// offset: 偏移量 从0开始
// 返回值:
// [{"id":"ae2a89f5ad89f3d78b7213e10710988c","text":"xxxxxxxx"}]
const res = await ttai_data.queryDocument(limit, offset)
// 删除数据 async deleteDocument(ids=[])
// ids: 过滤条件,指定删除的id数组 ids=["id1", "id2"]
// 返回值:
// true
const res = await ttai_data.deleteDocument(ids)
// 数据集详情 async describeCollection()
// 返回值:{count:0}
const res = await ttai_data.describeCollection()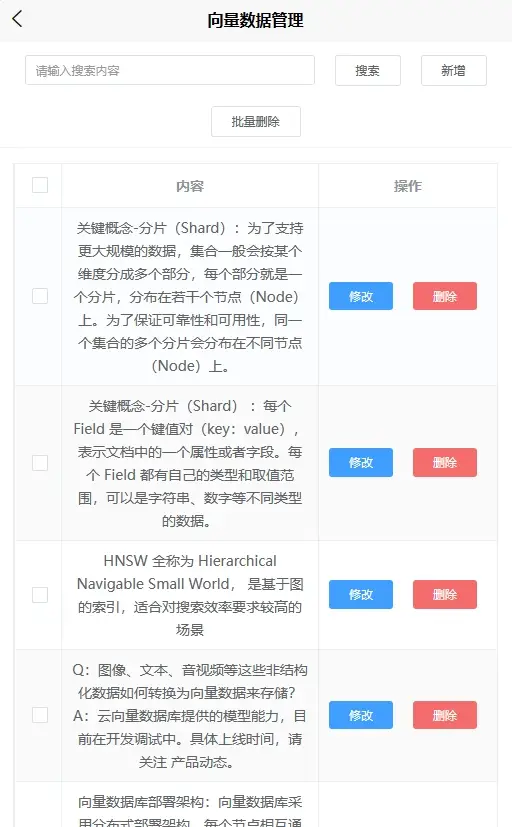
 下载 20
下载 20
 赞赏 0
赞赏 0

 下载 34714
下载 34714
 赞赏 158
赞赏 158







 赞赏
赞赏
 京公网安备:11010802035340号
京公网安备:11010802035340号